Insatiable need for more and more transistors
There has been a lot of discussion lately about hardware required to meet the needs of training and inferencing of all the AI/ML systems. Open AI cofounder Sam Altman asked for US$7 trillion to build out Semiconductor hardware for AIi. From the chip industry there is a goal of building 1 trillion transistor AI hardware in the near futureii. Almost all of this hardware will be build using 2.5D or 3D silicon design. There are other applications other than AI that will also require very high transistor count designs. Current microprocessors have multibillion transistors. For example, Intel Sapphire Rapids processor has 48 billion transistors, Nvidia NVLink network switch has about 25 billion transistors. It is easy to imagine that very soon some of these single package systems will hit a trillion transistors in the next few years.
As we venture into the realm of increasingly smaller process technologies, the challenge of producing these devices is compelling chip manufacturers to limit chip sizes, despite the rise in transistor densities. While systems stand to gain from a higher level of integration than what process technology deems optimal for chip size, we find ourselves in the midst of a hyper-scaling revolution in computing.
The advent of AI and Machine Learning, particularly Large Language Models (LLM) related generative AI applications, necessitates the construction of these systems. This has led to an awakening: the pace of silicon hardware development is lagging behind the advancement of Generative AI models, a point underscored in the paper “AI and Memory Wall” 1.
In essence, we’re racing against time, striving to bridge the gap between hardware capabilities and the demands of next-gen AI models. The future of computing hangs in the balance, and it’s a
race we cannot afford to lose.
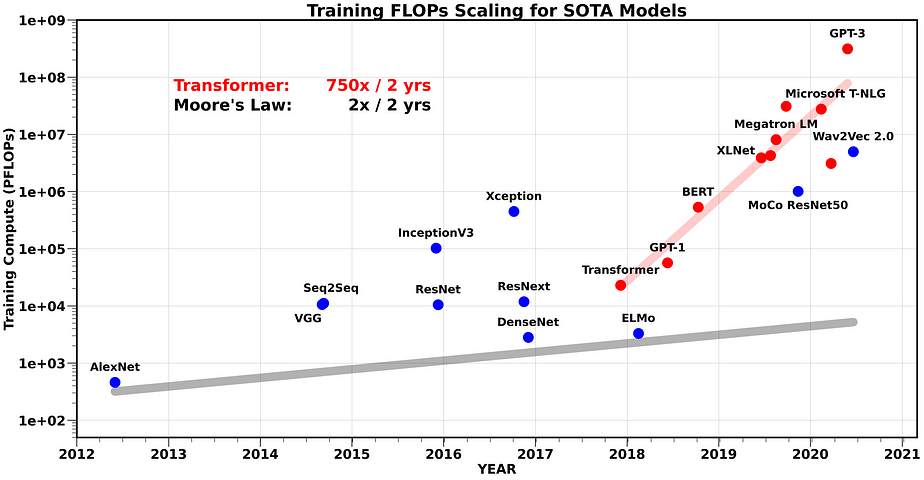
Fig1. AI learning and Moore’s Law. (AI and the memory wall.)
1 IEEE Micro, AI and memory Wall, 2024 early access. https://ieeexplore.ieee.org/document/10477550
As we push the boundaries of technology, we’re developing systems that scale beyond the confines of Moore’s Law. These systems leverage advanced packaging, 3D stacking, and hyper-scaled data centres to meet the growing demands of the digital age.
However, this scaling presents a significant challenge: energy efficiency. As we scale up, we must also ensure that our systems are energy-efficient, balancing performance with sustainability.
In response to these challenges, custom silicon is being developed for targeted model development. These bespoke solutions offer tailored performance, catering to specific needs and applications.
A key strategy in the development of these systems is the use of multi-chiplet designs. By connecting dies via silicon interposers, we can enhance the performance of the interconnect while conserving power. This approach offers a promising pathway to efficient, high-performance computing, setting the stage for the next generation of technological innovation.
In essence, we’re not just building systems; we’re shaping the future of computing. And in this future, efficiency and performance go hand in hand.
The challenges of building reliable devices
As we push the boundaries of technology, scaling is just one piece of the puzzle. Equally important is ensuring the Reliability, Availability, and Serviceability (RAS) of the systems we build. This means that even as we scale, our end-use systems must meet stringent quality-of-service requirements.
These requirements can be categorized into a few key areas. Some systems will need to meet regulatory safety requirements, others may be critical due to the domain in which they are deployed. Additionally, we may provide silicon and hardware into domains that aren’t critical, but customer agreements necessitate an elevated level of service quality.
The tech industry has faced challenges that require an enhanced level of quality. A prime example is silent data corruption. Historically, hardware has been plagued by this issue, often labelled as a soft error rate. However, analysis of single-bit errors in data centre DRAMs revealed that these so-called soft errors were recurring at the same memory locationiii. This indicates that these errors were not soft errors, but defects in the DRAM – defects in silicon that went undetected in production testing.
This highlights the fact that some of these defects are test escapes, which should have been detected through more rigorous testing. As we continue to innovate, we must also continue to refine our testing processes to ensure the highest quality in our systems. After all, in the world of technology, quality isn’t just a goal – it’s a necessity.
As we witness the rise of colossal data centres, housing over a million CPUs, the frequency of system defects, even with single or two-digit DPM, has surged. This phenomenon, increasingly reported in large data centres, is a testament to the challenges of operating at such a massive scale.
Research conducted at Meta has shed light on these errors. They discovered that silent data corruption led to decompression failures, with the file size of the corrupted data registering as “0”. This resulted in files failing to decompress, thereby causing errorsiv.
Google, too, has reported hardware errors. In response, they’ve published an application note detailing these hardware errors. Their solution? Implementing protective measures within their file system softwarev. This approach underscores the importance of robust software solutions in mitigating hardware issues.
In essence, as we scale up our digital infrastructure, we must also scale up our efforts to ensure reliability and error-resilience. After all, in the world of big data, it’s not just about size – it’s about stability, too.
Design for Test (DFT) and Test Engineering methodologies play a crucial role in identifying and isolating defective hardware. While some improvements can be achieved through more aggressive screening, in other cases, we need to develop better methodologies to identify defective parts.
As we construct silicon chiplets to be integrated into a packaged System in Package (SiP), it’s imperative that the SiP meets the standards of reliability, availability, and serviceability on par with a monolithic packaged system. It’s important to note that these chiplets can originate from various suppliers, not just the team packaging the SiP. This necessitates traceability for each chiplet, especially when the final product encounters a defect.
First and foremost, the SiP must be engineered to enable all manufacturing tests to be run on it. This is to isolate the component that is the root cause of the defect. This would require DFT for the SiP, enabling both structural and, if necessary, functional or System Level Test (SLT) patterns to be delivered to each chiplet, as tested during wafer test.
We need to execute the patterns for each chiplet at every insertion to identify any divergence from the original manufacturing test. This requires a device ID for each chiplet to identify each pattern run, considering the pattern version and the test program.
Given that these chiplets can come from different vendors, we need access to patterns from these vendors. Furthermore, we need to retarget the patterns from the vendor chiplet to the SiP top-level pins. This necessitates access to production data from different vendors.
As process technologies continue to evolve, feature sizes are shrinking to the point where they consist of only a few atoms and molecules. This miniaturization leads to increased process variations, prompting a revaluation of the minimum (Vmin) and maximum (Vmax) voltages for devices.
Increased parametric variations necessitate designs to margin timing and power with greater flexibility. To accommodate these changes, manufacturing processes must adopt more adaptive testing methodsvi. This ensures that parts are designed and architected to meet quality standards across broader ranges. The goal is to maintain the integrity and performance of the devices, despite the challenges posed by the continual push towards smaller feature sizes.
2.5D and 3D based SiP Test and Manufacturing
The upcoming generation of chiplet-based systems will feature a mix of 3D integrated devices and 2.5D chiplets. One potential shift could be a transition from silicon-based interposers to glass-based ones, although silicon-based interposers may still be in use.
At present, most designs are based on 2.5D integration of the logic chiplet. The High Bandwidth Memory (HBM) chiplet, which is a 3D Through-Silicon Via (TSV) stack, is currently in high-volume manufacturing.
As we progress, we can expect to see an increase in devices featuring in-memory or near-memory structures. This will dramatically boost the logic to-memory bandwidth, similar to the impact made by HBM memory, but with denser and wider TSV connections. This evolution signifies a promising future for chiplet-based systems.
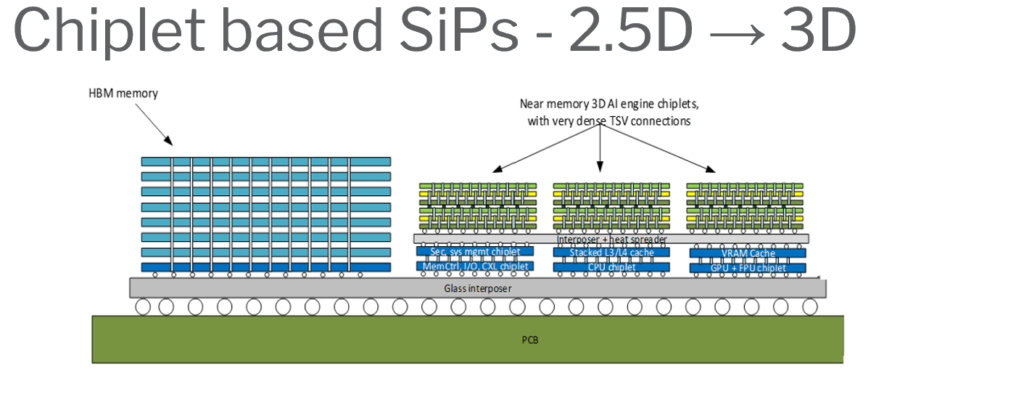
The manufacturing and testing of these devices present several key challenges :
- Delivering Known Good Dies for Individual Chiplets : Each planar chiplet must be verified to
function across all working corners and provide high coverage to ensure the yield of the
assembled System in Package (SiP) is not compromised. - Testing the Die-to-Die Interface in All Modes : Each known good die requires a pad loopback test design on its interface. This allows the connection of ingress and egress paths as a loopback, ensuring the interfaces are tested and function defect-free at full speed when connecting Die-to-Die interfaces across two chiplets.
- Running All Wafer Patterns on Partial and Fully Assembled SiP : The Design for Test (DFT) for the chiplets and the SiP must be designed to deliver the structural and System Level Test (SLT) patterns to each chiplet from the assembled SiP pins. Methodologies must be in place to retarget the pattern from a single wafer die to multiple dies across.
- Designing the SiP with Adequate Redundancy and Repair : Redundancy must be provided for resources on individual chiplets, enabling the repair of circuits in each mode incrementally. This allows defective circuits to be disabled and either use redundant resources or use the part with reduced functionality.
- Architecting the Chiplets and SiP for Power for Functional and Test Operation : The functional and structural test architecture must be designed to operate structural in low power mode without unduly compromising test time and cost.
- Enabling Repairability and Redundancy Programming in Final Package : The ability to recover a part with full or partial functionality, even when a defect is found late in the production cycle, is crucial for both high-performance parts and price-sensitive parts.
- Device ID for Every Die and SiP : Every die and the overall SiP should have a device ID. This ensures traceability of all chiplets and the overall SiP both in the field and in case of Return Merchandise Authorization (RMA) or system debug. Care must be taken to accord the correct privilege level to the requesting agent to ensure data protection.
- Device Security for Each Test Controller in Each Chiplet : Security must be provided for each test controller in each chiplet to prevent unauthorized access to the test infrastructure. Legitimate usage is allowed access to the required resources after due authentication. A uniform access mechanism framework must be provided for all security access mechanisms.
This blog will persist in delving deeper into each of the sub-topics, providing a platform for detailed discussions and exploration of the mechanisms. Your comments and suggestions are not only welcomed but also highly appreciated, as they contribute significantly to the further development of these ideas. Stay tuned for more insightful posts.
- https://www.wsj.com/tech/ai/sam-altman-seeks-trillions-of-dollars-to-reshape-business-of-chips-and-ai-89ab3db0
- https://spectrum.ieee.org/trillion-transistor-gpu
- Cosmic Rays Don’t Strike Twice: Understanding the Nature of DRAM Errors and the Implications for System Design: Hwang et. Al. ASPLOS’12, March 3–7, 2012
- HD Dixit, S Pendharkar, M Beadon, C Mason… – arXiv preprint arXiv …, 2021 – arxiv.org
- https://support.google.com/cloud/answer/10759085?hl=en
- R. Madge, B. Benware, R. Turakhia, R. Daasch, C. Schuermyer and J. Ruffler, “In search of the optimum test set – adaptive test methods for maximum defect coverage and lowest test cost,” 2004 International Conferce on Test, Charlotte, NC, USA, 2004, pp. 203-212, doi: 10.1109/TEST.2004.1386954.